
The (dark) magic of Unicode (posted 2022-01-30)
Way back in the 1960s, we had ASCII: the American Standard Code for Information Interchange. ASCII defined the 95 characters that still exclusively grace keyboards sold in English language countries. Apart from the letters a-z and A-Z, the digits 0-9 and the space, the ASCII characters are:
! " # $ % & ' ( ) * + , - . / : ; < = > ? @ [ ] ^ _ ` { | } ~ \
For English, where we typically type "cooperation" rather than "coöperation" these days, that's more or less sufficient. The idea was that in other languages, some of the less common characters would be replaced by accented letters or special characters common in that language. I don't think that really happened, though.
Instead, as ASCII is a 7-bit code and computers use 8-bit bytes to store data, various flavors of 8-bit "extended ASCII" were developed, like the MS-DOS code page 437 and Mac OS Roman. I'm pretty sure DEC's VT220 and higher terminals used various ISO 8859 variants, as did the Amiga. ISO-8859-1 (Latin-1) was also the default on the web early on.
However, these various 8-bit encodings weren't good enough: they'd miss “somewhat important” typographic characters and as scripts like Cyrillic and Greek were in different character sets / code pages, it wasn't possible to have both types of characters in the same text. And extended ASCII didn't work at all for many Asian scripts that require many more than 100 or so characters.
So: Unicode, an effort to encode all the scripts for all languages.
The simple version of the Unicode story is that today, we almost exclusively use the UTF-8 encoding, which will encode the full range of Unicode characters in a way that is very compatible with ASCII.
UTF-8
UTF-8 was a brilliant invention, so I have to talk about it. Originally, the idea was that Unicode would have 16-bit code points, so we'd simply have 16-bit characters rather than 8-bit characters. However, early Unicode support in Windows showed that this wasn't super easy, and certainly not very backward compatible. For instance, this is what I get when I try to display a UTF-16 file:
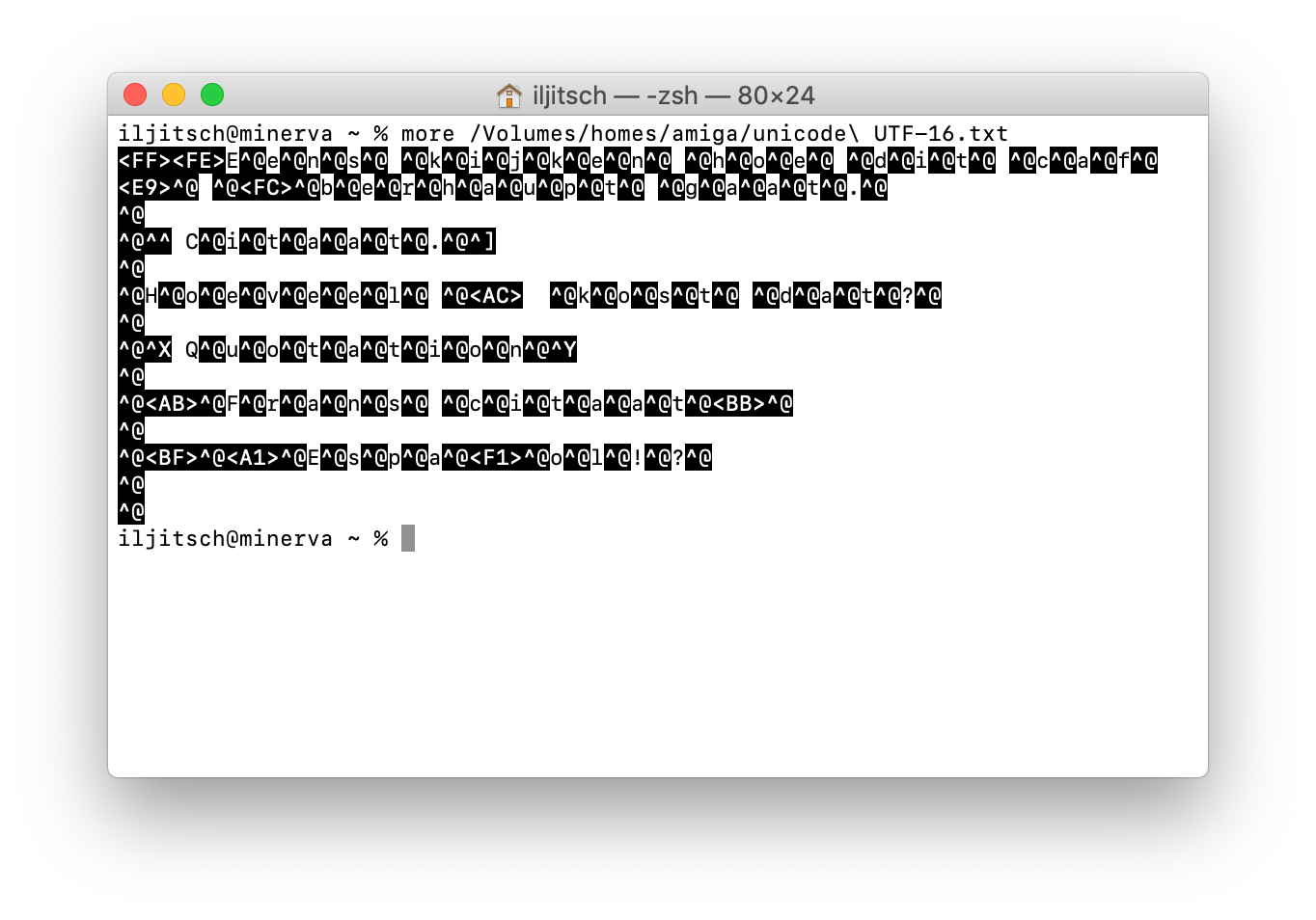 So interpreted as 8-bit characters, there's a zero byte between every two letters. And then they realized that 16 bits wasn't enough, anyway.
So interpreted as 8-bit characters, there's a zero byte between every two letters. And then they realized that 16 bits wasn't enough, anyway.
UTF-8 solves this by using a variable length encoding, where the first 128 characters are the same as in standard ASCII. So any ASCII file is a valid UTF-8 file. The rest of Unicode is encoded as two to four 8-bit non-ASCII characters. This works as follows:
- Code points 0 - 0x7F: 0xxxxxxx
- Code points 0x80 - 0x7FF: 110xxxxx 10xxxxxx
- Code points 0x800 - 0xFFFF: 1110xxxx 10xxxxxx 10xxxxxx
- Code points 0x1000 - 0x10FFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
So the worst thing that will happen to software that doesn't understand UTF-8 is that it shows some random accented characters rather than the intended character and UTF-8 doesn't generate any characters that may be interpreted as valid ASCII control characters or printable characters. Sorting and comparing strings will also work roughly as expected even if the software doesn't know about UTF-8.
Converting to UTF-8
These days in the 2020s, you really don't want to keep text files in any other encoding than UTF-8 unless you have a very particular reason to. To a somewhat lesser degree, this also goes for HTML files. But let's look at text files first.
If you have access to an old system in working order, a good way to work around the issue is to store files in Rich Text Format. This will encode non-ASCII characters in such a way that other applications will decode them correctly automatically.
But if you're not in the position to save text as RTF, or RTF is not a convenient destination format, you'll have to do a bit more work.
The first step is determining if conversion is necessary in the first place. The trusty Unix file command will recognize most file formats. If it says "ASCII", then the file only contains 7-bit ASCII characters, so it's valid UTF-8 in its current state. (On files originating from systems that didn't use extensions, such as the Amiga and classic Mac, it's helpful to add the .txt extension at this point.)
I'm not sure how file determines the encoding of text files that contain extended ASCII characters but aren't UTF-8. (UTF-8 is relatively easy to detect and other encodings rarely happen to be valid UTF-8.) So also consider where your text files came from.
If file says the text file is in a different format than ASCII or UTF-8, it's time to use the Unix iconv tool to convert the file.
Assuming a system set up in English or another western European language, files that come from the Amiga are in ISO-8859-1 (ISO Latin 1), those from classic MacOS are usually in Mac OS Roman (iconv: MACROMAN), MS-DOS files in 437 (CP437) or 850 (CP850) and Windows in Windows-1252 (CP1252). Windows-1252 is a superset of 8859-1 that fills in some of the unused code points in 8859-1.
This is the command for converting a Windows-1252 or ISO-8859-1 file to UTF-8:
iconv -f WINDOWS-1252 -t UTF-8 in-textfile >out-textfile.txt
Then, it's a good idea to check if the conversion gave us a UTF-8 file that looks correct. I use the following grep command for this, which is definitely not the best way to do it, but the only thing that seems to work on my Mac:
grep --color=auto "[¡-ÿ]" textfile.txt
Although not completely reliable, this will show you lines from your text file with the non-ASCII characters highlighted so you can see if they look like they've been converted correctly. (But if nothing looks right, it might be your shell that is not handling UTF-8 mode correctly, so open the files through other means to make sure.)
Unicode and the web
Originally, the web mostly used 8859-1. Or, actually Windows-1252, but claiming ISO-8859-1. Non-Windows users would often see �this� when a user typed "this" and Windows turned that into “this”. So now the HTML standard mandates that "ISO-8859-1" is taken to mean "Windows-1252". These days, almost all web pages are in UTF-8.
Browsers typically handle all the common encodings such as the ones mentioned above—but only if they're identified correctly. The HTTP server can do this in the HTTP response, or the HTML page can do this using the a meta tag:
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
Or just:
<meta charset="utf-8" />
Unfortunately, the character set in the HTTP server's response overrules the one in the meta tag of an HTML document. In practice, you'll want the server to tell browsers your pages are in UTF-8, as it's hard to make sure all pages use <meta charset="utf-8" />. And without any guidance, browsers are supposed to use ISO-8859-1, but many do something different so the user experience will not be consistent.
This is becoming less of an issue as time goes on, but it's not uncommon to have to create HTML using tools that don't handle UTF-8 correctly. Obviously if you're writing something with many non-ASCII characters, you'll want to make sure that Unicode/UTF-8 is handled correctly at every step.
But if you only need a few special characters here and there, or when using "untypable" characters, it's probably easier to just use the Unicode code point in an HTML entity, such as 😎 ("smiling face with sunglasses") 😎. However, this does decrease readability of the HTML code.
Unicode complexities and programming
If we go back to the earlier days of computing, things were simple: one character took up one byte of memory or disk space, and all characters took up the same amount of space on the screen. Then we got graphical user interfaces with variable-width fonts and what-you-see-is-what-you-get word processing. This broke the assumption that each character takes up the same amount of space on the screen.
Initially, the switch to Unicode didn't really (seem to) change the assumption that each character takes up one fix-size memory location. It's just that these memory locations were now twice as big: 16 bits rather than 8 bits (UCS-2 encoding).
However, from the start Unicode defined certain combining characters, such as combining diacritical marks. The ISO 8859 variants and other code pages simply use separate code points for each accented letter. So there is an ñ with ISO Latin 1 / Unicode code point Ñ. However, as no language uses an m with a tilde, there's no code point for that. But Unicode does in fact support putting any accent on any printable character by having the character in question followed by a combining diacritical mark. So m̃ produces m̃. But why stop there: m̼̃͛.
Which of course means that now one character on the screen can actually take up two or more Unicode code points. Support for another million code points on top of the original 65000 further complicates matters for UTF-16 and programming languages that use it, such as Javascript. Other languages, such as PHP, have special "multibyte" string functions, but these typically still don't fully implement the intricacies of Unicode combining and joining characters. So splitting up text strings can have unexpected results if you're slicing through a code point or set of code points that should have produced a single... character? glyph? grapheme? The terminology doesn't seem well-defined.
As noted above, code point Ñ produces ñ. But we can also type n and then the tilde combining diacritical mark ̃ and the product is the exact same ñ. However, one is still code point U+00D1 while the other is n + U+0303. So any software comparing the two will tell you they're different. As as you don't know if a text contains the precomposed form of accented characters or the decomposed form, you'll want to normalize the text strings in question before comparing or sorting them.
A while ago, I wrote a web tool that lets you add and remove accents from characters, have a look. It'll also let you copy the different normalization forms or the HTML entity encoded form of text with accents or other special characters.
Conclusions
It's great that we live in a time where our computers can work with pretty much any character used in any language written anywhere on the planet, and this pretty much works between operating systems and applications without issue.
Two groups of people need to pay a bit more attention: those of us working with old pre-Unicode text, and programmers. Sorry! 🤓